
kafka는 다음과 같은 기본 구성요소들이 있습니다.
1. producer(publisher, source application)
2. consumer(subscriber, target application)
3. broker
4. topic
5. partition
이번글에선 consumer에 대해 알아보겠습니다.
old/new
consumer에는 old/new consumer가 있습니다. 두 consumer의 가장 큰 차이는 zookeeper의 유무 입니다. kafka를 공부해보신분들이라면 최근들어 kafka가 zookeeper를 사용하지 않는다는 걸 들어보셨을겁니다. 왜 사용안하는지 검색하러 가실분들을 위해 간단하게 설명드리면
ZooKeeper stores persistent cluster metadata and handles maintaining dynamic configurations and topics, as well as partitions within the topics, he said. But ZooKeeper adds an extra layer of management. Storing metadata internally within Kafka will make managing it easier and enable better guarantees around issues such as versioning, according to McCabe.
zookeeper의 znode에 metadata를 저장하는 것이 관리에 추가적인 층을 형성해서 차라리 kafka내부에 저장하는 것이 유지보수하는 것이 더 편해서 라고 하네요.
아직까진 old consumer를 지원하고 있지만, 이후 해당 기능이 사라질 예정이므로 지금 kafka를 이용해 프로젝트를 시작하시는 분들은 new consumer를 기준으로 사용하시는 것이 좋겟습니다.
consumer
consumer의 역할은 다음과 같습니다.
1. consumer가 subscribe하는 topic의 partition으로 부터 polling
2. partition offset 위치 기록
3. consumer group을 통해 병렬처리
코드와 함께 알아보자면
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import java.util.Arrays;
import java.util.Properties;
public class ConsumerBasic {
public void receiveFromKafka() {
Properties props = new Properties();
props.put("bootstrap.servers", "127.0.0.1:9092");
props.put("group.id", "basic-consumer-group");
props.put("key.deserializer", "org.apache.kafka.common.serialization");
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
KafkaConsumer<String, String> consumer = new KafkaConsumer<String, String>(props);
consumer.subscribe(Arrays.asList("basic-consumer"));
try {
while (true) {
ConsumerRecords<String, String> records = consumer.poll(100);
for (ConsumerRecord<String, String> record : records) {
System.out.printf("Topic: %s, Partition: %s, Offset: %d, Key: %s, Value: %n\n",
record.topic(), record.partition(), record.offset(), record.key(), record.value());
}
}
} finally {
consumer.close();
}
}
}config 설정, consumer객체 생성, polling으로 이루어져있습니다.
데이터를 topic의 parition전부가아닌 특정 partition으로 부터 가져오고 싶다면
다음과 같이 assign 메소드를 사용하면 됩니다.
TopicPartition partition0 = new TopicPartition(topicName,0);
TopicPartition partition1 = new TopicPartition(topicName,1);
consumer.assign(Arrays.asList(partition0,partition1);
consumer의 핵심은 while문 안의 polling부분입니다.
broker로 부터 연속적으로 poll 메소드의 인자값으로 넘겨진 시간동안(ms)대기하여 대기한 시간동안 쌓인 많은 데이터를 가져 오는 것입니다.(consumer가 허락하는 한에서 말이죠)
다음은 offset에 대한 설명입니다.
offset
kafka에 대해 공부하다보면 빠질 수 없는것이 offset입니다.
그럼 offset이 뭐고 offset의 역할은 뭘까요?
offset의 정의는 상대적인 거리입니다.
뭔말이냐면 [0,1,2,3,4,5,6,7,8]의 리스트가 있다면 3기준으로 5까지의 offset은 2입니다.
kafka에선 시작 주소를 기준으로 offset을 매기므로 간단히 데이터가 들어간 순서로만 이해하셔도 될거 같습니다.
kafka에서 offset은 각 topic의 partition마다 또 해당 topic을 subscribe하는 consumer group마다 따로 매겨집니다.
그럼 offset은 왜 기록해야 할까요?
각 consumer그룹은 offset을 __consumer_offset topic에 저장됩니다.
이는 consumer가 죽었을때 offset정보가 있다면 consumer재실행시 어디까지 데이터를 읽었는지 알 수 있으므로 데이터의 처리시점을 복구할 수 있습니다.
consumer group
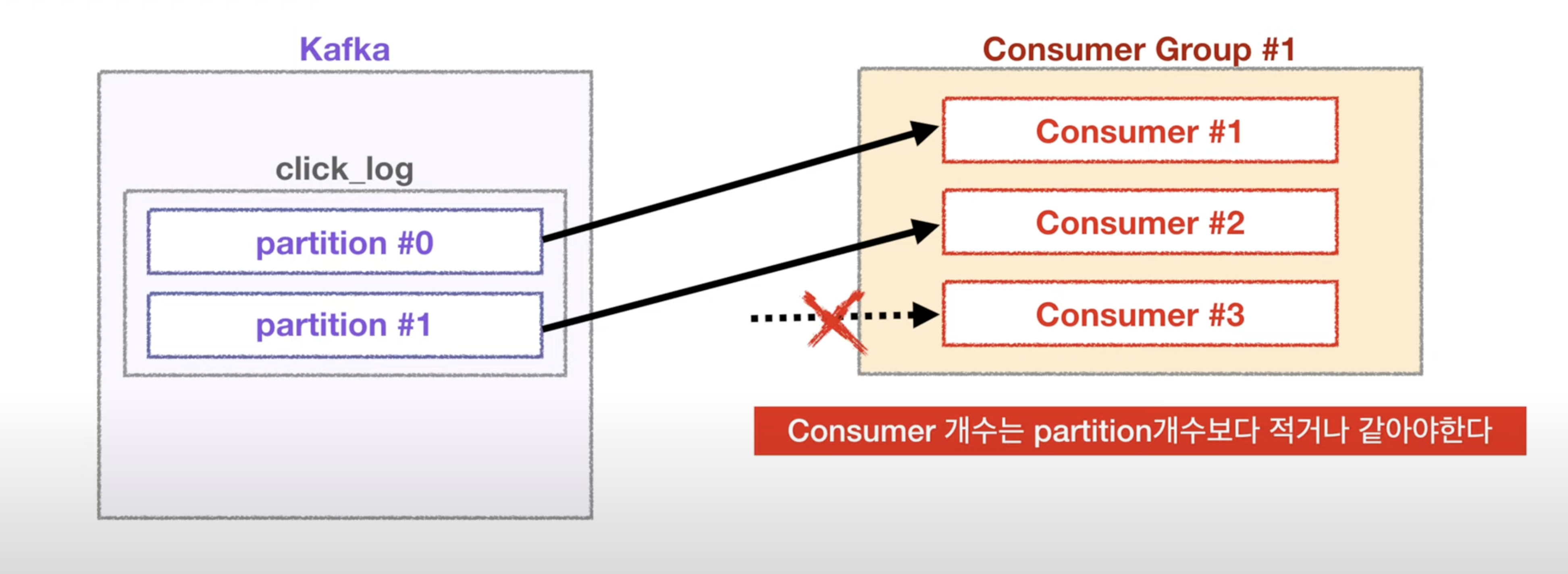
한 커슈머 그룹에서는 한 topic내에서 파티션과 consumer그룹의 consumer가 일대일 대응입니다.
파티션2 컨슈머1인 경우 파티션2개가 모두 컨슈머1에 할당되지만
파티션2 컨슈머3인 경우 컨슈머의 하나는 작동을 하지 않습니다.
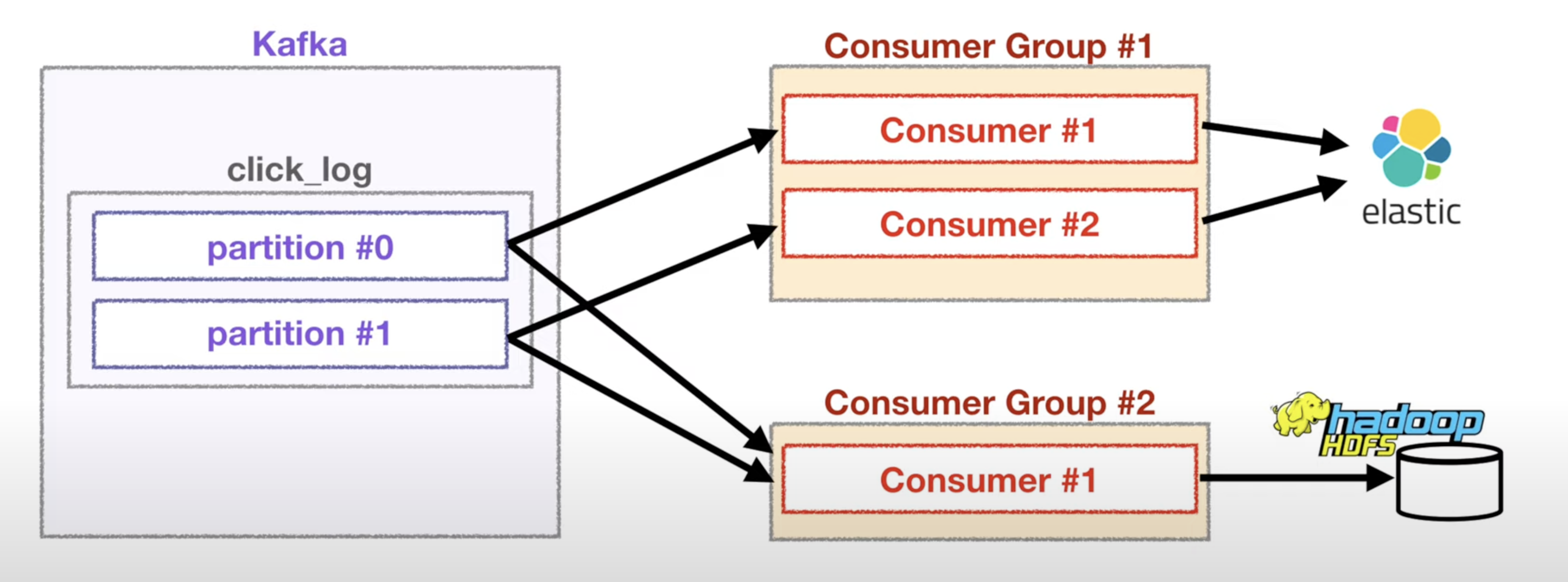
하지만 서로 다른 consumer 그룹의 경우 partition도 여러 곳에 데이터를 줄 수 있습니다.
또 위에서 말했듯 offset은 consumer group마다 따로 매겨지므로 서로 데이터를 읽는데에 영향을 끼치지 않습니다.
config
conumser의 설정값에는
fetch.min.bytes : 한번에 가져오는 데이터의 최소값
fetch.max.wait.ms : 데이터의 최소값이 충족되지 않았을 경우 최대 얼마나 기다릴지
fetch.max.bytes : 한번에 가져오는 데이터의 최대값
group.id : 컨슈머가 속한 컨슈머 그룹 식별자
enable.auto.comiit : 백그라운드에서 주기적으로 offset을 커밋할지
auto.commit.interval.ms : 주기적으로 offset을 커밋하는 시간
session.timeout.ms : consumer로부터 heartbeat가 설정값보다 늦게오면 장애가 있다 판단해 리밸런싱(컨슈머의 소유권 양도) 시도
heartbeat.inteval.ms : conumser가 broker에게 heartbeat를 보내는 주기
max.poll.records : 단일 호출에 대한 최대레코드 수
max.poll.interval.ms : 컨슈머가 heartbeat만 보내고 데이터를 가져가지 않을 경우를 고려해 consumer가 주기적으로 poll을 요청하지 않을 경우 장애라 판단 이후 해당 컨슈머를 제외하고 다른 컨슈머가 장애가 있는 컨슈머가 점유하고 있던 파티션으로부터 데이터를 가져갈 수 있도록 함
등등 이 있습니다.
'분산처리' 카테고리의 다른 글
| airflow에서 크롤링(selenium) 할 경우 무한대기 (0) | 2023.10.17 |
|---|---|
| kafka의 기본 구성요소들 broker, topic, partition (0) | 2023.01.14 |
| kafka의 기본 구성 요소들 producer (0) | 2023.01.09 |
| Kafka를 사용하는 이유 (1) | 2023.01.09 |